Kevin Cuzner's Personal Blog
Electronics, Embedded Systems, and Software are my breakfast, lunch, and dinner.
A New Blog
Jan 06, 2024
For the past several years I've struggled with maintaining the wordpress blog on this site. Starting 3 or 4 years ago the blog began to receive sustained stronger than usual traffic from data centers trying to post comments or just brute-forcing the admin login page. This peaked around 2021 when I finally decided to turn off all commenting functionality. This cooled things down except for requiring me to "kick" the server every few days as it ran out of file handles due to some misconfiguration on my part combined with the spam traffic.
This became annoying and I needed to find something that would be even lower maintenance. To that end, I've written my first functioning blogging software since 2006 or so. There is no dynamic content, all of it is statically rendered, and the blog content itself is stored in GitHub with updates managed using GitHub hooks. The content itself is written with ReStructured Text and I think I've created a pretty easy-to-use and low-maintenance blog platform (famous last words). Ask me in a decade if I was actually successful lol.
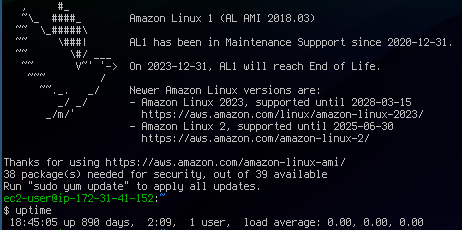
In addition, I've found that there are newer, cheaper AWS instances that would suit my needs. I started using this instance over 10 years ago and before I shut it down, I had an uptime of almost 2.5 years. It's truly the end of an era:
Contents
Concept
ReStructured Text
One of my biggest frustrations with wordpress, belive it or not, was its WYSIWYG editor. While it looked good, I found it to be inconsistent and more geared towards sharing opinions (and pictures) of coffee cups than presenting technical content. Also, as time went on wordpress kept changing things about its editor and not in ways that I liked. Furthermore, plugins and such for things like code blocks that once worked stopped working over the course of the 15 years or so that I ran that blog.
To solve the editing problem, I turned to ReStructured Text, or ReST. This is the markup language used in Python documentation (docutils) and by the Sphinx documentation tool. I've been using it quite extensively at work in a crusade against inadequate or badly maintained documentation and fell in love with the expressiveness available in contrast to other solutions such as Markdown.
Content Management with Git
Having now chosen ReST as a markup language, the next problem was the editor itself. Every time I've had to select an editor for web applications I end up missing my editor of choice (vim). So, why not just allow myself to use vim as my editor for writing blog posts?
With that thought, the idea for how this blog would work began to form:
- I'd store the blog content in a git repository as loose rst files (one file per post) and images. Perhaps I'd organize the posts into folders and place the images next door to the relevant rst file.
- A custom rst directive would be used to configure blog settings such as the post date, post title, tags, and such. All metadata about a post could be stored in the rst file, eliminating the need for any kind of database to store that information.
- I'd have something, perhaps written in Python to keep things easy, which would be triggered by a push to the repository on GitHub via a webhook. It would download the repository storing the content and render it into HTML.
- More than just storing the rst, the content repository could also store the entire website theme, written as Jinja2 templates. It could even store settings for the website, such as how many posts per page would be displayed, in a toml file.
Importing from Wordpress to ReST
I wanted to preserve all of my existing content that I had written, despite the "cringe" that I feel as I read things I wrote almost 15 years ago. To accomplish this I decided to write an importer that could take a standard Wordpress XML export and translate it into ReST, annotating each post to be compatible with this blog.
The importer is rather extensive and can be found here. It performs 3 main operations:
- Loading and decoding the XML, sorting the attachments (images), pages, and posts by their metadata.
- Translating "Wordpress HTML" into ReST and organizing the file structure in the content repository.
- Copying in attachments by downloading them from the existing website and placing them by their corresponding posts.
Most every HTML element supported by Wordpress is translated into something equivalent in ReST, though I had to give up on a few things such as mixing inline styles (in particular, bolded links) and so there are a few warts in the imported pages that I'll have to manually correct eventually.
Execution
Configuration Management with Docker
Another problem I faced with my 15 year old blog was server management. When I first started it I hosted it on a machine running out of my parent's basement. I soon migrated to a VPS on Rackspace (remember those days?) as hardware failures plagued that old basement server. I remained on Rackspace for a few years, but constantly had issues with heavy swapping during high load times. I decided to try AWS and it's been smooth sailing for nearly 10 years now. Unfortunately, the VPS that I was using on AWS is (as of December 31, 2023) deprecated and no longer receiving security updates.
I have less time on my hands now than I did 15 years ago with a demanding job, a family, and a house to maintain. The prospect of recreating and managing the server (a task I relished back in the day) felt nothing but daunting. I've become jaded the past few years in regards to server management and have realized that I hate infrastructure management (IT or Sysadmin work). So, I needed to find a solution where I could "set it and forget it".
The world has come a long way in the past decade in regards to scripted configuration, with containers remaining a primary underpinning technology. They allow for each subpart of an application to essentially live in its own "virtual machine"-like environment and eliminate issues of dependency or other conflicts that impact interoperability. The docker-compose tool takes things a step farther, allowing a multi-container configuration to be described with connections between the containers.
Static rendering of the content
For "set it and forget it" to work, I need to minimize how often I log into the server. The idea is that when I push to the content repository, I'd like the server to automatically fetch the update and update itself to match. This is accomplished by way of github webhooks. When a push occurs, the webhook will hit a URL (authenticated via HMAC) which will cause the repo to be pulled and the content rerendered.
I probably did not do this the most efficient way, but what I settled on was an interaction beween Flask and Celery, using Redis to facilitate message passing. Flask declares an endpoint like this:
1@app.route("/refresh", methods=["POST"])
2@validate_hmac
3async def request_refresh():
4 worker.update.delay()
5 return {}
My worker module declares a Celery task that pulls the repo and then initiates rendering the content into a folder:
1@app.task
2def update():
3 """
4 Updates the repo and re-renders all content
5 """
6 import glob, shutil
7 from jinja2 import Environment, FileSystemLoader, select_autoescape
8
9 repo_dir = Path(settings["repository"]["directory"]).resolve()
10 logger.info(f"Updating {repo_dir}")
11 with working_dir(repo_dir):
12 subprocess.check_output(["git", "remote", "-v"])
13 subprocess.check_output(["git", "fetch"])
14 subprocess.check_output(["git", "reset", "--hard", "origin/main"])
15 subprocess.check_output(["git", "clean", "-fdx", "."])
16 ...
All of this code can be found in the rstblog repo.
Nginx as a content server
Now that I have a folder containing the rendered blog HTML, I have to serve it. Rather than doing this via Python, I decided instead to use nginx to simply serve the content statically. My hope is that this ends up being much more robust than Wordpress ever was in the face of DDOS attacks.
This is orchestrated by having an nginx container and worker container share the folder that the content is rendered into as a volume:
1services:
2 redis:
3 image: "redis:5-alpine"
4 restart: always
5 nginx:
6 build:
7 context: ./nginx
8 restart: always
9 ports:
10 - "3000:80"
11 depends_on:
12 - "web"
13 volumes:
14 - content:/app/output
15 web:
16 build: .
17 command: gunicorn -k gevent --access-logfile - -b 0.0.0.0:5000 'app:app'
18 restart: always
19 depends_on:
20 - "redis"
21 worker:
22 build: .
23 command: poetry run celery -A worker worker -l debug
24 restart: always
25 depends_on:
26 - "redis"
27 volumes:
28 - content:/app/output/html
29
30volumes:
31 content:
Nginx itself serves as the main gateway for the content, but for certain URLs will defer to the Flask-based webapp that handles maintenance like refreshing the content:
1server {
2 listen 80;
3 server_name localhost;
4
5 absolute_redirect off;
6
7 location / {
8 root /app/output;
9 index index.html index.htm;
10 }
11
12 location /app {
13 rewrite /app(.+) $1 break;
14 proxy_pass http://web:5000;
15 proxy_redirect off;
16
17 proxy_set_header Host $host;
18 proxy_set_header X-Real-IP $remote_addr;
19 proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
20 proxy_set_header X-Forwarded-Proto $scheme;
21 }
22...
A better way to do this might have been to use the try_files nginx command, but this method should prevent a maliciously (or unintentionally) named file from preventing access to the refresh endpoint. I haven't tested that though, so we'll see how it goes.
Hosting
As I mentioned, I've hosted this website in many forms over the past while and since it had been 10 years since I last reevaluated, it was high time that I make sure I'm not running something entirely out of date.
The many ways to host docker containers on AWS
AWS still dominates the market today for VPS, so I decided to see if AWS had any way to host Docker containers natively, perhaps at a cheaper rate than EC2. What I discovered was this fun article (which I surmise was written as something of a joke): The 17 ways to run containers on AWS.
Long story short, AWS has a lot of offerings for hosting containers. They're geared towards all shapes and sizes of applications, but it does seem an awful lot of them are geared towards services that require something beyond "small". The footprint of this website is not very large and I don't get that many visitors. To that end, I've decided to go with the simplest of options: Hosting containers directly on a single EC2 instance.
Systemd service units
One of my constant struggles with running a server has been remembering what I had configured. To resolve that, I've decided to make my entire server configuration (aside from SSL) part of a repo. The repo is arranged like so:
1(root)/
2 +--- service1/
3 | +----- Dockerfile
4 | +----- docker-compose.yml
5 | |
6 | ...
7 +--- service2/
8 | +----- Dockerfile
9 | +----- docker-compose.yml
10 | |
11 +--- kevincuzner-com.target
12 +--- kevincuzner-com@.service
Each "service" is constructed using a docker-compose.yml file living in a subdirectory, likely containing at least one Dockerfile. Some of these subdirectories (specifically, the one for rstblog, the main blog website) are submodules pointing to other git repos. Through this method, I can keep all my configuration versioned, I can leave good comments to myself, and I'm not entirely at the mercy of having to remember how to configure the particular Amazon-provided linux distribution I'm using.
I also had the thought of perhaps having each service run as an actual service on the machine, so it can automatically start and such. To that end, I've declared a very simple wildcard systemd unit, kevincuzner-com@.service:
1[Unit]
2Description=%i kevincuzner.com service
3After=docker.service
4Wants=docker.service
5PartOf=kevincuzner-com.target
6
7[Service]
8type=oneshot
9RemainAfterExit=true
10WorkingDirectory=/srv/docker/%i
11ExecStart=/usr/bin/docker compose up --build -d --remove-orphans
12ExecStop=/usr/bin/docker compose down
13
14[Install]
15WantedBy=multi-user.target
And I've declared a very simple kevincuzner-com.target target that I use for aggregating and declaring all of the services that make up my website:
1[Unit]
2Description=kevincuzner.com server target
3After=docker.service
4Wants=docker.service
5Wants=kevincuzner-com@http.service
6Wants=kevincuzner-com@rstblog.service
7Wants=kevincuzner-com@email.service
8
9[Install]
10WantedBy=multi-user.target
There is a circular dependency between each of the services and the target. The target declares itself as Want-ing each service unit. Conversely, each unit declares itself as PartOf the target. This allows me to do things like start, stop, and restart the target and have it stop, start, and restart all of the services.
Interactions between HTTP services
Services such as the rstblog need to be communicated with by a top-level HTTP server which also delegates to the other services. I went through a few iterations on how to accomplish this and realized a few things:
- Docker compose by default isolates all containers, volumes, and networks for a service. And it makes it hard to overcome this isolation, probably by design.
- It's possible for a service to access the network or a volume created by another service, but it's hard to get all the hostnames working right. I had a tough time getting nginx in one service group to recoginize the hostname of an nginx instance in another group.
- I don't need isolated communications between the service groups. And all of them take over some host port for communication with the outside world.
With that final bullet point, I realized that all I needed to do was:
- Segment services by data. If two services needed to access the same data (postfix and dovecot, for example, both need access to mailboxes) then they should either be part of the same service group, or they should use a directory on the host machine (and I plan to do for SSL certificates and such).
- Reference only the host in inter-service communciation. For example, my rstblog is mounted on a port in the vicinity of 3000 and so the nginx running on the host's port 80 just needs to forward appropriate requests to the host.docker.internal:3000, never knowing that it's actually taking to the rstblog's nginx service.
To summarize, I either use directly mounted folders on the host or reference other services by treating them as the host (via the host.docker.internal hostname) in order to share data between my service groups. For example, my top-level nginx configuration looks something like this:
1server {
2...
3 location / {
4 try_files $uri @rstblog;
5 index index.html index.htm;
6 }
7
8 location @rstblog {
9 proxy_pass http://host.docker.internal:3000;
10 proxy_redirect off;
11 ...
12 }
13...
14}
Conclusion
The above culminates about 2.5 calendar years of work trying and researching how to revamp my website so that it's easier for me to manage in the future. All in all, I've probably only spent about 80 hours on it, but life gets busy. I'm also extremely distractible and I've been working on 3 or 4 hobby projects at the same time, so this fell to the wayside pretty often. Truthfully, I only wrapped it up because the AWS Linux image I was using had reached the absolute end of its support period.
With this change, I get to end my days of having to manage a PHP & MySQL server. In a way, it's the end of an era. I got my start almost 20 years ago writing websites for the LAMP stack and all that remains now is the "L".
See ya later PHP, wouldn't want to be ya!
websites server python
Recent posts
Search through tags with mini.pick in neovimWriting reusable USB device descriptors (and other constant data) with C++ constexpr
Using "access" types and "new" in VHDL
A New Blog
A good workflow and build system with OpenSCAD and Makefiles